
Quick LLM API pricing comparison
I put this together for my own personal projects to compare practical model options across providers. The main question is whether it is worth going deeper into hardware-focused inference providers for speed, and how much extra that speed would cost versus standard API routes. I might’ve missed some details or better options, when pulling or analyzing the data, ofc.
Data snapshot collected and compared on: 2026-02-25
Scope
- Compare selected LLM API prices using a consistent unit. I added some notes which I found interesting for my cases.
- Normalize all token prices to USD per 1M tokens.
- For hardware-focused providers in this post (Groq, SambaNova, Cerebras) I checked only text models.
- There is tons of benchmarks and arguments about them, so no point to overanalyze for quick check. I use scores from Artificial Analysis (by the state at 2026-02-25) as a rough proxy to compare relative quality. My personal model preferences mostly (but not fully) correlate with it.
Raw data first
Pricing comparison
| Provider | Model | Input ($/1M tokens) | Output ($/1M tokens) | Context window | Notes | Source |
|---|---|---|---|---|---|---|
| gemini-3.1-pro-preview | 2.00 (<=200k prompt), 4.00 (>200k prompt) | 12.00 (<=200k prompt), 18.00 (>200k prompt) | Tiered at 200k prompt tokens | Google Search: 5,000 prompts/month free, then 14.00 per 1,000 search queries | https://ai.google.dev/gemini-api/docs/pricing | |
| gemini-3-pro-preview | 2.00 (<=200k prompt), 4.00 (>200k prompt) | 12.00 (<=200k prompt), 18.00 (>200k prompt) | Tiered at 200k prompt tokens | Google Search: 5,000 prompts/month free, then 14.00 per 1,000 search queries | https://ai.google.dev/gemini-api/docs/pricing | |
| gemini-3-flash-preview | 0.50 (text/image/video), 1.00 (audio) | 3.00 | Not specified here | Google Search pricing same as Gemini 3 Pro/3.1 Pro note above | https://ai.google.dev/gemini-api/docs/pricing | |
| gemini-2.5-flash | 0.30 (text/image/video), 1.00 (audio) | 2.50 | Not specified here | Search: 1,500 RPD free (shared with Flash-Lite RPD), then 35.00 per 1,000 grounded prompts | https://ai.google.dev/gemini-api/docs/pricing | |
| Anthropic | Claude Opus 4.6 | 5.00 | 25.00 | Not specified here | Standard API pricing | https://platform.claude.com/docs/en/about-claude/pricing |
| Anthropic | Claude Opus 4.5 | 5.00 | 25.00 | Not specified here | Standard API pricing | https://platform.claude.com/docs/en/about-claude/pricing |
| Anthropic | Claude Sonnet 4.6 | 3.00 | 15.00 | Not specified here | Standard API pricing | https://platform.claude.com/docs/en/about-claude/pricing |
| Anthropic | Claude Haiku 4.5 | 1.00 | 5.00 | Not specified here | Standard API pricing | https://platform.claude.com/docs/en/about-claude/pricing |
| OpenAI | GPT-5.2 | 1.750 | 14.000 | Not specified here | Standard API pricing | https://openai.com/api/pricing/ |
| OpenAI | GPT-5.2 pro | 21.00 | 168.00 | Not specified here | Standard API pricing | https://openai.com/api/pricing/ |
| OpenAI | GPT-5 mini | 0.250 | 2.000 | Not specified here | Standard API pricing | https://openai.com/api/pricing/ |
| OpenAI | gpt-4o | 2.50 | 10.00 | Not specified here | Included for comparison | https://openai.com/api/pricing/ |
| Groq | GPT OSS 20B 128k | 0.075 | 0.30 | 128k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | GPT OSS Safeguard 20B | 0.075 | 0.30 | Not specified here | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | GPT OSS 120B 128k | 0.15 | 0.60 | 128k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | Kimi K2-0905 1T 256k | 1.00 | 3.00 | 256k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | Llama 4 Scout (17Bx16E) 128k | 0.11 | 0.34 | 128k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | Llama 4 Maverick (17Bx128E) 128k | 0.20 | 0.60 | 128k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | Qwen3 32B 131k | 0.29 | 0.59 | 131k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | Llama 3.3 70B Versatile 128k | 0.59 | 0.79 | 128k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| Groq | Llama 3.1 8B Instant 128k | 0.05 | 0.08 | 128k | Current speed listed on page (see speed table below) | https://groq.com/pricing |
| SambaNova | DeepSeek-R1-Distill-Llama-70B | 0.70 | 1.40 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | DeepSeek-V3-0324 | 3.00 | 4.50 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | DeepSeek-V3.1 | 3.00 | 4.50 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | DeepSeek-V3.1-cb | 0.15 | 0.75 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | DeepSeek-V3.1-Terminus | 3.00 | 4.50 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | DeepSeek-V3.2 | 3.00 | 4.50 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | E5-Mistral-7B-Instruct | 0.13 | 0.00 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | gpt-oss-120b | 0.22 | 0.59 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | Llama-3.3-Swallow-70B-Instruct-v0.4 | 0.60 | 1.20 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | Llama-4-Maverick-17B-128E-Instruct | 0.63 | 1.80 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | Meta-Llama-3.1-8B-Instruct | 0.10 | 0.20 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | Meta-Llama-3.3-70B-Instruct | 0.60 | 1.20 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | MiniMax-M2.5 | 0.30 | 1.20 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | Qwen3-235B | 0.40 | 0.80 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| SambaNova | Qwen3-32B | 0.40 | 0.80 | Not specified here | Text model | https://cloud.sambanova.ai/plans/pricing |
| Cerebras | ZAI GLM 4.7* | 2.25 | 2.75 | Not specified here | Preview model marker * shown on pricing page |
https://www.cerebras.ai/pricing |
| Cerebras | GPT OSS 120B | 0.35 | 0.75 | Not specified here | Standard row in developer tier pricing table | https://www.cerebras.ai/pricing |
| Cerebras | Llama 3.1 8B | 0.10 | 0.10 | Not specified here | Standard row in developer tier pricing table | https://www.cerebras.ai/pricing |
| Cerebras | Qwen 3 235B Instruct* | 0.60 | 1.20 | Not specified here | Preview model marker * shown on pricing page |
https://www.cerebras.ai/pricing |
I took mostly models which are interesting to me + text models available on hardware providers and served with a very high speed relative to normal GPU serving. Obviously, there is more to analyze and it’s also possible to pull private api speeds. Maybe later :)
Rows not present (especially several SambaNova DeepSeek variants) are kept as pricing references and are not used in score-based picks above.
Stated generation speed
| Provider | Model / Scope | Speed | Notes | Source |
|---|---|---|---|---|
| Groq | GPT OSS 20B 128k | 1,000 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | GPT OSS Safeguard 20B | 1,000 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | GPT OSS 120B 128k | 500 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | Kimi K2-0905 1T 256k | 200 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | Llama 4 Scout (17Bx16E) 128k | 594 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | Llama 4 Maverick (17Bx128E) 128k | 562 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | Qwen3 32B 131k | 662 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | Llama 3.3 70B Versatile 128k | 394 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Groq | Llama 3.1 8B Instant 128k | 840 TPS | Listed as “Current Speed (Tokens per Second)” | https://groq.com/pricing |
| Cerebras | ZAI GLM 4.7* | ~1000 tokens/s | Developer tier pricing table | https://www.cerebras.ai/pricing |
| Cerebras | GPT OSS 120B | ~3000 tokens/s | Developer tier pricing table | https://www.cerebras.ai/pricing |
| Cerebras | Llama 3.1 8B | ~2200 tokens/s | Developer tier pricing table | https://www.cerebras.ai/pricing |
| Cerebras | Qwen 3 235B Instruct* | ~1400 tokens/s | Developer tier pricing table | https://www.cerebras.ai/pricing |
Personal local hardware runs (gpt-oss-120b, llama.cpp server)
These are my own rough measurements and are not directly comparable to provider-reported benchmarks:
- MacBook Pro M4 Max (16 cores): ~300 TPS input (prefill), ~70 TPS output (decode)
- NVIDIA GB10: ~1,000 TPS input (prefill), ~50 TPS output (decode)
Prefill and decode are different phases. Prefill parallelizes over prompt tokens; decode is sequential and often bottlenecked by KV-cache traffic, kernel efficiency, quantization path, and small-batch utilization. So it is normal to see input TPS and output TPS behave differently.
For hardware context:
- NVIDIA DGX Spark lists 273 GB/s memory bandwidth: https://www.nvidia.com/en-us/products/workstations/dgx-spark/
- Apple M4 Max memory bandwidth depends on configuration (for example 410 GB/s and 546 GB/s variants): https://support.apple.com/en-us/121553
So bandwidth alone is probably not the full explanation for my prefill/decode imbalance. Something to dig deeper into later too.
Shared models (hardware providers + 2-3 cheapest OpenRouter models)
This is a model-family normalization. No GPT OSS 120B quantization row because GPT OSS 120B is MXFP4 out of the box.
| Normalized model family | Groq ($/1M in, out) | SambaNova ($/1M in, out) | Cerebras ($/1M in, out) | OpenRouter routes ($/1M in, out, TPS) | Cheapest input (all) | Cheapest output (all) |
|---|---|---|---|---|---|---|
| GPT OSS 120B | 0.15, 0.60 | 0.22, 0.59 | 0.35, 0.75 | DeepInfra 0.039, 0.19 @ 70 TPS; NovitaAI 0.05, 0.25 @ 58 TPS | OpenRouter (DeepInfra) | OpenRouter (DeepInfra) |
| Kimi K2.5 | – | – | – | DeepInfra 0.45, 2.25 @ 15 TPS; SiliconFlow 0.45, 2.25 @ 12 TPS; Nebius 0.50, 2.50 @ 9.5 TPS. Direct moonshot.ai: 0.10, 0.60 (TPS not listed) | Direct moonshot.ai | Direct moonshot.ai |
| GLM-5 | – | – | – | SiliconFlow 0.95, 2.55 @ 29 TPS (FP8, 204.8k in/131k out); AtlasCloud 0.95, 3.15 @ 28 TPS (FP8, similar context); Friendli 1.00, 3.20 @ 22 TPS (202.8k in/out). Direct z.ai: 1.00, 3.20 | OpenRouter (SiliconFlow/AtlasCloud tie) | OpenRouter (SiliconFlow) |
| GLM-4.7 | – | – | 2.25, 2.75 | io.net 0.30, 1.40 @ 45 TPS (BF16, 202.8k); DeepInfra 0.40, 1.75 @ 31 TPS (FP4, 202.8k); Nebius 0.40, 2.00 @ 46 TPS (FP8, 202.8k). Direct z.ai: 0.60, 2.20 | OpenRouter (io.net) | OpenRouter (io.net) |
| Llama 3.1 8B | 0.05, 0.08 | 0.10, 0.20 | 0.10, 0.10 | NovitaAI 0.02, 0.05 @ 29 TPS (FP8); DeepInfra 0.02, 0.05 @ 36.5 TPS (BF16) | OpenRouter (DeepInfra/NovitaAI tie) | OpenRouter (DeepInfra/NovitaAI tie) |
| Llama 4 Maverick 17B-128E | 0.20, 0.60 | 0.63, 1.80 | – | DeepInfra 0.15, 0.60 @ 30 TPS (BF16); NovitaAI 0.27, 0.85 @ 42 TPS (FP8) | OpenRouter (DeepInfra) | Groq / OpenRouter DeepInfra (tie) |
| Qwen3 32B | 0.29, 0.59 | 0.40, 0.80 | – | DeepInfra 0.08, 0.28 @ 46 TPS (FP8); Nebius 0.10, 0.30 @ 8 TPS (FP8); NovitaAI 0.10, 0.45 @ 36 TPS (FP8, 20k max output) | OpenRouter (DeepInfra) | OpenRouter (DeepInfra) |
| Qwen3 235B | – | 0.40, 0.80 | 0.60, 1.20 | DeepInfra 0.071, 0.10 @ 14 TPS (FP8); Weights & Biases 0.10, 0.10 @ 23 TPS (BF16); NovitaAI 0.09, 0.58 @ 14 TPS (FP8, 16.4k max output) | OpenRouter (DeepInfra) | OpenRouter (DeepInfra / Weights & Biases tie) |
OpenRouter model pages used:
- https://openrouter.ai/openai/gpt-oss-120b?sort=price
- https://openrouter.ai/meta-llama/llama-3.1-8b-instruct?sort=price
- https://openrouter.ai/meta-llama/llama-4-maverick?sort=price
- https://openrouter.ai/qwen/qwen3-32b?sort=price
- https://openrouter.ai/qwen/qwen3-235b-a22b-2507?sort=price
- Kimi K2.5 and GLM route prices/TPS were added from OpenRouter.
Artificial Analysis screenshots
Sources:
Extracted scores from screenshots
Reasoning/non-reasoning tags are kept in model names where relevant.
| Model | General index | Coding index | Agentic index |
|---|---|---|---|
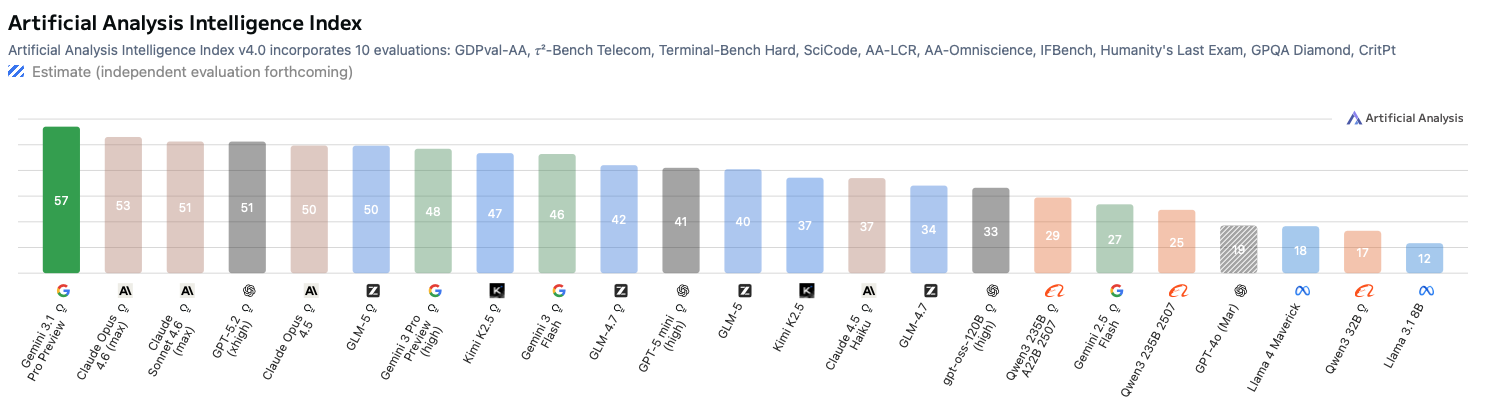
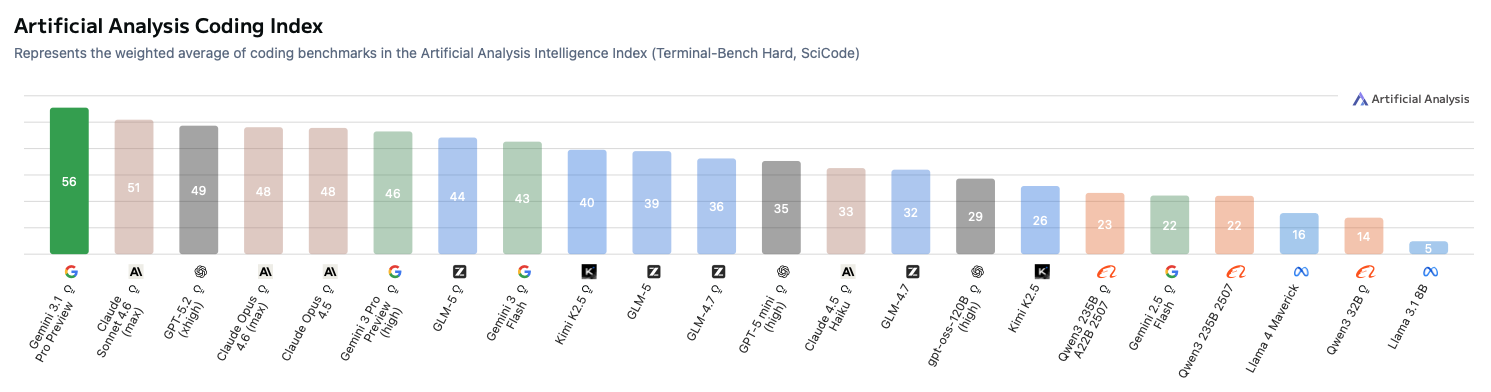
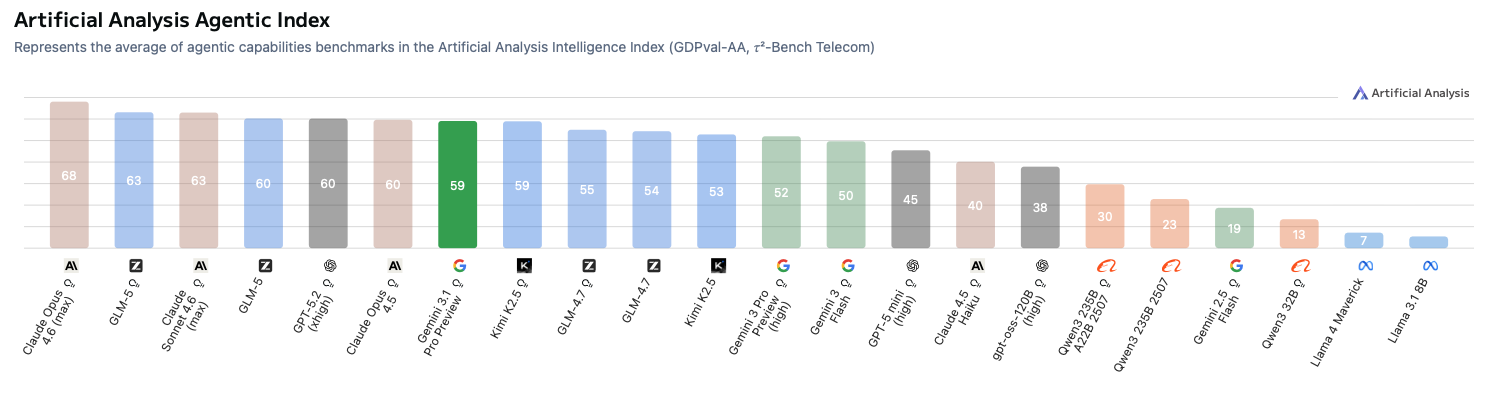
| Gemini 3.1 Pro Preview | 57 | 56 | 59 |
| Claude Opus 4.6 (max) | 53 | 48 | 68 |
| Claude Sonnet 4.6 (max) | 51 | 51 | 63 |
| GPT-5.2 (xhigh) | 51 | 49 | 60 |
| Claude Opus 4.5 | 50 | 48 | 60 |
| GLM-5 (reasoning) | 50 | 44 | 63 |
| Gemini 3 Pro Preview (high) | 48 | 46 | 52 |
| Kimi K2.5 (reasoning) | 47 | 40 | 59 |
| Gemini 3 Flash | 46 | 43 | 50 |
| GLM-4.7 (reasoning) | 42 | 36 | 55 |
| GPT-5-mini (high) | 41 | 35 | 45 |
| GLM-5 (non-reasoning) | 40 | 39 | 60 |
| Kimi K2.5 (non-reasoning) | 37 | 26 | 53 |
| Claude Haiku 4.5 | 37 | 33 | 40 |
| GLM-4.7 (non-reasoning) | 34 | 32 | 54 |
| gpt-oss-120B (high) | 33 | 29 | 38 |
| Qwen3 235B A22B 2507 (reasoning) | 29 | 23 | 30 |
| Gemini 2.5 Flash | 27 | 22 | 19 |
| Qwen3 235B A22B 2507 | 25 | 22 | 23 |
| GPT-4o (Mar) | 19 | – | – |
| Llama 4 Maverick | 18 | 16 | 7 |
| Qwen3 32B | 17 | 14 | 13 |
| Llama 3.1 8B | 12 | 5 | 5 |
General Intelligence Index
Coding Index
Agentic Index
Key takeaways
- Benchmark-wise for coding quality, Gemini 3.1 Pro is the top score; Sonnet 4.6 and GPT-5.2 are close alternatives.
- For coding-heavy day-to-day use, fixed monthly plans usually beat pure token billing on effective cost at this point in time.
- For cheap bulk processing, Llama 3.1 8B still wins pure token price, and in my experience with heavy prompting it can still do surprisingly well for simple annotation/summarization/extraction; gpt-oss-120B often buys better output for only a small cost bump.
- Benchmark-wise for deep conversation quality, Gemini 3.1 Pro is the best default; Opus 4.6 is the premium agentic option.
- For low-latency UX, Groq/Cerebras throughput is a different class (hundreds to thousands TPS), often worth a modest token premium.
- GLM-5 and Kimi K2.5 are the most interesting value outliers, with good benchmark indices but slower OpenRouter route TPS.
Recommendations by use-case
Default routing table
| Scenario | Default model | Upgrade model | Fast-path model | Ultra-cheap batch model |
|---|---|---|---|---|
| Coding | Gemini 3.1 Pro | Claude Sonnet 4.6 / GPT-5.2 | Gemini 3 Flash | Kimi K2.5 (reasoning) / GLM-5 (reasoning) |
| Mass processing | gpt-oss-120B (cheap route) | GPT-5 mini / Gemini 3 Flash | Groq/Cerebras Llama 3.1 8B | Llama 3.1 8B (DeepInfra/Novita) |
| Deep conversation | Gemini 3.1 Pro | Claude Opus 4.6 | – | GLM-5 (reasoning) / Kimi K2.5 (reasoning) |
| Casual conversation | GPT-5 mini / Gemini 3 Flash | gpt-oss-120B (Groq) | Groq Llama 3.1 8B / Groq gpt-oss-120B | Llama 3.1 8B |
| Agents | Claude Sonnet 4.6 / GPT-5.2 / Gemini 3.1 Pro | Claude Opus 4.6 | – | GLM-5 (reasoning) |
Coding
Factors:
- Coding Index for solve/compile reliability.
- Output token cost (coding answers are often output-heavy).
Practical ladder:
- Benchmark leader: Gemini 3.1 Pro (Coding Index 56), with frontier pricing that is still below Opus-tier.
- Strong alternatives: Claude Sonnet 4.6 (Coding 51) or GPT-5.2 (Coding 49). GPT-5.2 is cheaper than Sonnet for prompt-heavy coding.
- Good enough and cheap: Gemini 3 Flash (Coding 43) for small refactors, snippets, and explain-this-code tasks.
- Budget value outliers: GLM-5 (reasoning) and Kimi K2.5 (reasoning), if you can tolerate lower route TPS and occasional misses.
Personal experience note:
- In my own use, Gemini is strong on LeetCode-style coding but less consistent as an independent coding agent for project-aware restructuring and style-matching. Results seem to vary a lot across users, prompting style, and workflow setup.
For a typical coding call (10k input + 2k output):
- Gemini 3.1 Pro: ~$0.044
- GPT-5.2: ~$0.0455
- Claude Sonnet 4.6: ~$0.060
- Gemini 3 Flash: ~$0.011
Pricing model note (important for real coding usage):
- Today it is generally better to use fixed plans for coding rather than pay per token.
-
Most major vendors with coding assistants (Claude, Codex/OpenAI tooling, GLM ecosystem, and others) offer fixed plans with limits that are usually high enough for individual workflows.
- Llama 3.1 8B was not made for coding
- gpt-oss-120B is alright for local coding support (coding score 29).
For coding, the ladder is clear: Flash/mini for cheap edits, Gemini 3.1 Pro when correctness matters, Sonnet/GPT-5.2 as strong alternates.
Quick mass processing for simple tasks
What matters:
- Cost per item and throughput (items/second).
Short answer:
- Llama 3.1 8B still wins pure token economics.
- gpt-oss-120B is often a better default now: still cheap, substantially stronger, and can be faster depending on route/provider.
Per-item comparison for 1k input + 100 output:
- Llama 3.1 8B (cheapest OpenRouter route): ~$0.000025/item (~40k items per $1), about 30-36 TPS on listed routes.
- gpt-oss-120B (DeepInfra route): ~$0.000058/item (~17k items per $1), about 70 TPS, and much stronger benchmark profile.
- Llama 3.1 8B (Groq): ~$0.000058/item, ~840 TPS.
- Llama 3.1 8B (Cerebras): ~$0.00011/item, ~2200 tokens/s.
Recommended bulk pipeline:
- Tier 0 (ultra-cheap): Llama 3.1 8B for easy formatting/tagging/extraction.
- Tier 1 (still cheap, fewer retries): gpt-oss-120B for brittle schemas or light reasoning.
- Tier 2 (correctness-heavy): GPT-5 mini or Gemini 3 Flash when failure/retry cost dominates.
Llama 3.1 8B still wins pure token economics, but gpt-oss-120B is the key “pay a little more, fail less” option.
Deep conversations
Factors:
- General Intelligence Index as proxy for coherence/nuance.
- Context tiering and output pricing.
Good options across categories:
- Best default (quality + reasonable cost): Gemini 3.1 Pro (General 57, output $12/1M at <=200k prompt tier).
- Premium quality tier: Claude Opus 4.6 (General 53, Agentic 68) if cost is secondary.
- Budget surprises: GLM-5 (reasoning) and Kimi K2.5 (reasoning), with strong indices for listed prices but lower route TPS.
Personal preference note:
- For chat quality/feel, my own preference is ChatGPT Pro (subscription, not rich enough to try the api) > Opus 4.6 > Gemini Pro, even though data ranks Gemini 3.1 Pro highest by numbers.
For long, high-quality conversations, Gemini 3.1 Pro is the clean default. Opus is the premium experience.
Casual conversation
Factors:
- Cost per turn and streaming latency.
Picks:
- Cheap + good proprietary defaults: GPT-5 mini or Gemini 3 Flash.
- Snappy streaming first: Groq routes (especially Llama 3.1 8B or gpt-oss-120B).
- Local privacy/offline option: local gpt-oss-120B is already in a usable chat band from my own runs.
Agents
Factors:
- Agentic Index and cost per step (agent loops amplify both token cost and failure cost).
Picks:
- Max reliability: Claude Opus 4.6 (Agentic 68), expensive but highest score.
- Strong mid-tier brains: Claude Sonnet 4.6, GPT-5.2, Gemini 3.1 Pro.
- Budget outlier: GLM-5 (reasoning), strong Agentic score for its listed prices, with lower route TPS.
- Better as subroutines than planners: Llama 3.1 8B / Llama 4 Maverick / Qwen3 32B / Qwen3 235B (low Agentic scores here).
Agent workloads amplify both token and failure costs. Opus is premium, Sonnet/GPT-5.2/Gemini are strong mid-tier, GLM-5 is the most interesting budget agentic outlier.
Typical token-cost scenarios (token-cost only)
Formula used:
cost = (input_tokens / 1,000,000 * input_price) + (output_tokens / 1,000,000 * output_price)
Chat turn (baseline): 3k input + 1k output
| Model | Cost per turn |
|---|---|
| GPT-5 mini | ~$0.00275 |
| Gemini 3 Flash | ~$0.00450 |
| Gemini 3.1 Pro (<=200k tier) | ~$0.01800 |
| Claude Opus 4.6 | ~$0.04000 |
Mass processing: 1k input + 100 output
| Model/route | Cost per item | Items per $1 | Notes |
|---|---|---|---|
| Llama 3.1 8B (OpenRouter DeepInfra/Novita) | ~$0.000025 | ~40,000 | Cheapest token route |
| gpt-oss-120B (OpenRouter DeepInfra) | ~$0.000058 | ~17,241 | Better quality/success profile |
| Llama 3.1 8B (Groq) | ~$0.000058 | ~17,241 | Much faster streaming |
| Llama 3.1 8B (Cerebras) | ~$0.000110 | ~9,091 | Throughput-focused option |
Coding: 10k input + 2k output
| Model | Cost per call |
|---|---|
| Gemini 3.1 Pro (<=200k tier) | ~$0.0440 |
| GPT-5.2 | ~$0.0455 |
| Claude Sonnet 4.6 | ~$0.0600 |
| Gemini 3 Flash | ~$0.0110 |
Agent step: 3k input + 500 output
| Model/route | Cost per step |
|---|---|
| Claude Opus 4.6 | ~$0.0275 |
| Claude Sonnet 4.6 | ~$0.0165 |
| GPT-5.2 | ~$0.01225 |
| Gemini 3.1 Pro (<=200k tier) | ~$0.0120 |
| GLM-5 (OpenRouter SiliconFlow route) | ~$0.004125 |
Pareto-front view (textual)
- Coding Index: Gemini 3.1 Pro is the top score; Sonnet/GPT-5.2 are close; Gemini 3 Flash and GPT-5 mini are cheap practical points.
- Agentic Index: Opus is the top point; Sonnet/GLM-5/GPT-5.2 cluster as strong alternatives at lower cost.
- Bulk processing: Llama 3.1 8B gives the leftmost cost point; gpt-oss-120B often gives the better cost-to-reliability trade.
Caveats
- Vendor TPS is not apples-to-apples (different batch sizes, output lengths, queueing, and serving conditions).
- Tokenization and effective context behavior vary by model/provider.
- Agent cost is multiplicative by number of calls, not just per-call token prices.
- Route-level prices/TPS can change quickly;
Conclusions
- Output pricing still dominates many real workloads, especially coding and long-form conversations.
- Gemini 3.1 Pro is the best default frontier pick today across quality and token economics.
- GPT-5.2 vs Sonnet is close on benchmark scores, with GPT-5.2 usually cheaper in prompt-heavy flows.
- GLM-5 is the biggest anomaly here: Sonnet-tier Agentic score in this table with much lower listed route pricing, at lower TPS.
- Kimi K2.5 looks like a second anomaly if direct
0.10 / 0.60pricing is stable. - Open-weight fast routes are excellent for cheap subroutines and throughput, but still weak as primary agent planners.
- Local gpt-oss-120B decode (~70 TPS in my runs) is roughly on par with the cheapest cloud route in this table, while hosted hardware providers still dominate absolute decode throughput.
- For coding-heavy daily work, fixed monthly plans are usually the best deal in this timeframe; token APIs stay useful as overflow, batch, or integration rails.
Personal hardware usage
For my local llama.cpp server runs with gpt-oss-120b, the two machines behave like different profiles:
- M4 Max: ~300 TPS prefill / ~70 TPS decode
- NVIDIA GB10: ~1000 TPS prefill / ~50 TPS decode
Interpretation:
- Prefill TPS mostly affects time to first token (especially with large prompts).
- Decode TPS mostly affects streaming speed after generation starts.
Quick intuition table (sequential, no batching):
| Scenario (prompt / output) | M4 Max time | GB10 time | Feels better |
|---|---|---|---|
| Simple extraction (1k / 100) | ~4.8s | ~3.0s | GB10 |
| Casual chat (1k / 200) | ~6.2s | ~5.0s | GB10 |
| Deep chat turn (3k / 1k) | ~24.3s | ~23.0s | Slight GB10 |
| Coding with context (10k / 1.5k) | ~54.8s | ~40.0s | GB10 (big) |
| Agent step (4k / 300) | ~17.6s | ~10.0s | GB10 (big) |
These are estimated as:
total_time ~= prompt_tokens / prefill_TPS + output_tokens / decode_TPS
Rule of thumb from these measurements:
- GB10 wins when prompts are large and outputs are moderate (RAG/context-heavy coding, agent traces, tool logs).
- M4 Max catches up only when output is very large relative to prompt.
- Crossover is around
output_tokens >= 0.4 * prompt_tokens.
Where local hardware fits best:
- Coding: good offline copilot for refactors, boilerplate, and iteration without cost anxiety; still use stronger frontier models when correctness is critical.
- Mass processing: GB10 is the stronger local box for prefill-heavy pipelines; for pure simple bulk, smaller 8B cloud routes are usually more efficient.
- Deep conversations: very usable for private long-form chat, but quality/speed still below frontier hosted options.
- Casual conversation: good privacy-first default; not in the same latency class as Groq/Cerebras.
- Agents: better as a cheap local subroutine executor than a primary planner brain.
Practical takeaway:
- Local
gpt-oss-120bsits in a useful “privacy-first, no-marginal-cost, mid-speed” tier. - It complements cloud inference well: use local for private/iterative inner loops, cloud for highest reliability or fastest UX.